
交互式学python
今天突然看到一个非常nice的python交互式学习网站,因为看到是莫烦PYTHON,所以打开了,发现宝藏!!!
希望通过学习,进一步提高自己的代码能力,加油!😄
首先,温习一下我的markdown语法
markdown官方语法网站:
https://markdown.com.cn/basic-syntax/
以下是cute emojis
https://gist.github.com/rxaviers/7360908
Python 安装和依赖管理
依赖是什么
我们在运行一个 Python 程序的时候,你很有可能需要依赖于其他人写的代码,或者仓库,而这就是 Python 的依赖。 比如你在学习机器学习,你很有可能就要依赖于下面这些库来写代码:
①tensorflow
②pytorch
③sklearn
④numpy
pip
安装依赖的方法:
conda install 和 pip
- pip是最底层最原始的 Python 库管理工具,安装一个 Python 就自带一个 pip,每个版本的 Python 都有自己私有的 pip。你可以想象成 pip 是 Python 的跟班。
- conda 是在 pip/python 之上,想要隔离 pip 和 Python 环境的组件,所以是用 conda 来管理不同的 python 版本的。
pip 安装及卸载方法,pip安装具有通用性,兼容:1
2
3
4
5pip install numpy # 安装最新的 numpy
pip install numpy matplotlib requests # 一次性安装多个依赖
pip install numpy==1.19.4 # 强制安装特定版本的库
pip install -i https://mirrors.cloud.tencent.com/pypi/simple numpy # 使用国内镜像源安装,可以加速下载
pip uninstall numpy # 卸载 numpy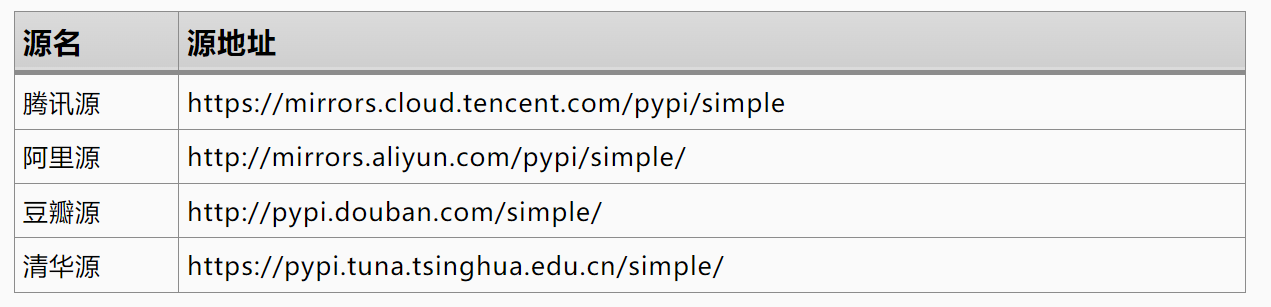
conda分项目管理
首先,你需要创建一个 conda 环境 env,定义这个环境的名字和 Python 版本。
1 | conda create --name mofanpy python=3.8 |
然后手动切换到这个 mofanpy 的环境中,不然你就会一直待在一个叫 base 的基础环境中。
1 | conda env list # 可以看到当前有哪些环节 |
然后在你新建的环境中,直接用 pip 安装你想要安装的库吧,现在所有用 pip 安装的库,都会隔离开,单独存放在 mofanpy 这个独立环境中。和 base 或者其他环境都不影响。 当然如果你懂 conda install xxx 你也可以使用这个指令来安装依赖,这种方法同样也是隔离的安装方式。
python基础语法
这里只写一些我不太熟悉的
判断、循环、数据
条件判断
- if;if not
- if-else
- if-elif-else
判断条件 and or not:
True and True
True or False
not True
for 和 while 循环
- for:适合有限循环
- while:可用在无限循环,不知道什么时候停止-可以用条件来限制循环次数
1
2
3
4num = 10
while num != 20:
num+= 1
print(num) - break 和 continue
为了避免无限次循环,我们可以使用一个计数器count来计数,限制循环次数。或者利用break1
2
3
4
5
6count = 0
guess_num = 30
while guess_num != 20 and count <= 10:
guess_num -= 1
count += 1
print(guess_num) - break:跳出循环
1
2
3
4
5
6
7
8count = 0
guess_num = 30
while guess_num != 20 :
guess_num -= 1
count += 1
if count > 10:
break
print(guess_num) - continue:跳过本次循环,继续下一次循环
1
2
3
4for i in range(10):
if i % 2 == 0:
continue # 跳过偶数
print(i)
数据种类
- int、float、str、list(列表元素有顺序)
- dict字典(元素没有顺序)
key键,不可变(标签);value值,可变,通过key可以修改相应的value1
2
3
4
5files = {"ID": 111, "passport": "my passport", "books": [1,2,3]}
print(files)
print(files["books"])
files["ID"] = 222
print(files) - tuple元组
元组功能比较单一,元素不可变,只能读,不能改1
2files = ("file1", "file2", "file3")
print(files[1]) - set集合
set如其名,就是数学里的集合,里面没有重复元素,且无序。 {% tabs Tags %}{'file3', 'file2', 'file1'} {'file3', 'file2', 'file1'} {'file4', 'file3', 'file2', 'file1'} {'file4', 'file2', 'file1'} your_files {'file5', 'file3', 'file1'} 交集 {'file1'} 并集 {'file5', 'file4', 'file3', 'file2', 'file1'} 补集 {'file5', 'file3'} {% endtabs %}1
2
3
4
5
6
7
8
9
10
11
12
13my_files = set(["file1", "file2", "file3"])
print(my_files)
my_files.add("file3")
print(my_files)
my_files.add("file4")
print(my_files)
my_files.remove("file3")
print(my_files)
your_files = {"file1", "file3", "file5"}
print("your_files", your_files)
print("交集 ", your_files.intersection(my_files))
print("并集 ", your_files.union(my_files))
print("补集 ", your_files.difference(my_files))
自带功能
.keys();.values();.items()
{% tabs Tags %}1 | files = {"ID": 111, "passport": "my passport", "books": [1,2,3]} |
列表.append();.pop()
{% tabs Tags %}1 | files = [] |
1 | files = ["f1.txt", "f2.txt"] |
字典.get();.update()
{% tabs Tags %}1 | files = {"ID": 111, "passport": "my passport", "books": [1,2,3]} |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles


Comment